2.3 Температура и надежность динамичного ОЗУ (DRAM)
2.3.1 Освещение проблемы и исходные данные
В этом разделе рассматривается влияние температуры на надежность DRAM, которое является одним из наиболее часто заменяемых аппаратных компонентов в дата-центрах и одной из самых распространенных аппаратных причин отказа узлов [30, 31]. DRAM имеет два разных вида ошибок: исправимые ошибки (CE), при которых переключаются отдельные биты на микросхеме DRAM, но которые можно исправить с помощью встроенной кода исправления ошибок (error correcting codes, ECC); и неисправимые ошибки (UE), при которых переключается множество битов, и число ошибочных битов является слишком большим для того чтобы ECC могла их исправить, и это вызывает фатальный сбой или выключение. Причиной исправимых ошибок (CE) могут быть внешние помехи, например, космические лучи, или аппаратные дефекты, например, залипающий бит. Причиной неисправимых ошибок обычно являются дефекты базового оборудования, так как очень маловероятно, чтобы космические лучи могли вызвать одновременное переключение такого большого число битов, чтобы это могло привести к неисправимой ошибке. Поэтому во многих ЦОД принято сразу заменять DRAM DIMM после первого случая возникновения неисправимой ошибки.
В работе [32] рассматриваются исправимые ошибки в DRAM, и показывается зависимость повышения их частоты от температуры, но делается вывод, что эта корреляция исчезает при включении управления загрузкой. В этом разделе рассматривается влияние температуры на долгосрочную надежность DRAM, а не вероятность временных проблем, т.e. влияние повышенных температур на быстроту износа DRAM и необходимости его замены.
При изучении долгосрочной надежности DRAM использовались такие методы как анализ данных по замене модулей DIMM, данных по отказам узлов, которые связаны с DRAM, и данных по неисправимым ошибкам, так последние два события могут быть признаком аппаратных проблем и, как правило, ведут к замене DIMM. Мы получали данные из трех разных источников:
Google: Google регулярно собирает данные по случаям исправимых и неисправимых ошибок во всех своих дата-центрах, а также периодически снимает показания датчиков температуры на материнской плате. Обзор системы измерений Google представлен в [32]. Для своего исследования мы получали данные по выбранной совокупности систем Google, охватывающих десяток разных центров. Дата центры основаны на пяти различных аппаратных платформах, где аппаратная платформа определяется материнской платой и поколением запоминающего устройства. Технические характеристики аппаратных платформ считаются конфиденциальной информацией и поэтому мы называем их просто Платформами A, B, C, D, E, F.
Лос-Аламосская национальная лаборатория (Los Alamos National Lab, LANL): LANL предоставила данные по отказам узлов в более чем 20 своих высокопроизводительных вычислительных кластерах, включая информацию по главным причинам отказов и продолжительности отказов. Данные можно скачать с веб-страницы LANL [1], а более детальное описание данных и систем можно найти в [30]. Неисправимые или фатальные ошибки DRAM были одной из самых распространенных причин отказов, и в этом разделе используется только подгруппа данных по отказам узлов, связанных с DRAM.
По одному из кластеров LANL есть периодические показания датчиков температуры на материнской плате, что позволяет нам непосредственно изучать взаимосвязь между температурой и отказами. Мы называем эту систему LANL-system-20, поскольку на веб-странице LANL этой системе присвоен ID 20. По другим 12 кластерам есть информация по топологии ЦОД, включая положение каждого узла в стойке. Мы использовали положение в стойке в качестве индикатора температуры, так как в связи с конструкцией системы охлаждения, в этих кластерах температура обычно выше в верхней, а не в нижней части стойки. Мы проверили это, проанализировав данные по LANL-system-20, в которых присутствуют фактические показания температуры, и узнали, что разность температуры между верхом и низом стойки составляет 4°C. Эти 12 кластеров основаны на двух различных аппаратных платформах, которые мы называем LANL-Type-1 и LANL-Type-2.
LANL-Type-1 включает в себя семь кластеров LANL, состоящих из 2720 узлов и 20880 процессоров. Все системные узлы имеют симметричную мультипроцессорную архитектуру (SMP) с 4 процессорами на узел и работают на базе одной и той же аппаратной платформы. Данные по этим системам охватывают 2002—2008 годы и соответствуют системам с IDs 3,4,5,6,18,19 и 20 на веб-странице LANL.
LANL-Type-2 включает в себя шесть кластеров LANL, состоящих из 1664 узлов и 3328 процессоров. Узлы представляют собой SMP с 2 процессорами на узел, и данные по этим система охватывают 2003—2008 гг. Эти данные также доступны на веб-странице LANL и соответствуют системам с идентификаторами ID 9, 10,11,12,13 и 14.
SciNet-GPC: Суперкомпьютерный консорциум SciNet предоставляет вычислительные ресурсы исследователям в Канаде. В настоящее время их универсальный кластер General Purpose Cluster (GPC) является самым большим суперкомпьютером в стране [2]. Мы получили от них данные по замене элементов оборудования, которые вручную вводятся администратором при замене неисправного оборудования. Полученный нами журнал замен охватывает 19 месяцев. GPC состоит из 3870 узлов IBM iDataPlex, размещенных в 45 стойках. Каждый узел содержит по два 8-ядерных процессора Intel Xeon E5540 CPU и 16 ГБ памяти с функцией ECC.
2.3.2 Анализ
На рисунке 7 показана ежемесячная вероятность отказа узлов LANL, которые связаны с проблемами памяти, вызываемыми изменением средней температуры узла. На рисунке 7 (слева) мы используем данные по LANL-system-20, которые содержат результаты фактических измерений температуры, а на Рис. 7 (в центре, справа) мы используем положение сервера в стойке в качестве индикатора температуры для систем LANL-Type-1 и LANL-Type-2. Мы пришли к заключению, что ни один из графиков не дает явного подтверждения повышения частоты отказов узлов вместе с повышением температуры.
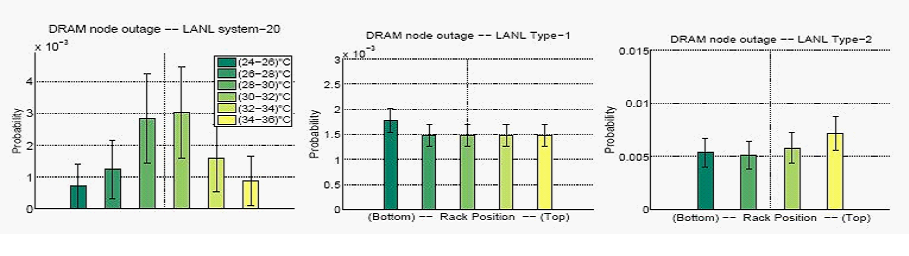
Рисунок 7: Вероятность отказа узлов LANL, связанных с проблемами DRAM, в зависимости от температуры (слева) и положения стойки (посередине, справа).
Результаты являются схожими по частоте замены оборудования в SciNet. На Рис. 8 показана ежемесячная вероятность замены модуля DIMM в узле в зависимости от его положения в стойке. И опять мы не увидели никаких признаков повышения частоты отказов в более высоких (и отсюда более горячих) положениях стойки.
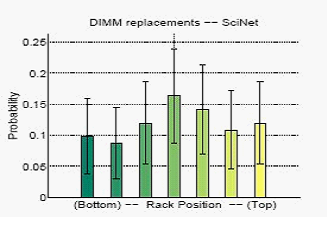
Рисунок 8: Замена модулей памяти DIMM в SciNet.
К сожалению, в связи с размером совокупности данных «усы» ошибок на этих графиках относительно высокие. Поэтому мы обратились к данным по неисправимым ошибкам, предоставленным Google, которые представляют собой совокупность данных датасет большего размера. На рисунке 9 (слева) показана ежемесячная вероятность неисправимых ошибок DRAM для пяти различных аппаратных платформ в Google. Мы пришли к заключению, что для двух моделей, моделей C и F, частота ошибок оставалась стабильной в пределах предоставленного диапазона температуры, который был довольно большим и составлял 15-60°C. Что может показаться удивительным, модели D и A показали противоречивые закономерности, при этом в первой наблюдалось снижение частоты при повышении температуры, а в последней – повышение частоты при повышении температуры. Для исследования возможной причины мы разбили данные по центрам обработки данных. На рисунке 9 (справа) показан раздел по дата-центрам для модели D. Мы пришли к заключению, что частота ошибок для индивидуальных ЦОД в основном не изменяется с температурой, за исключением одного дата-центра (datacenter-2). Именно совокупность данных из разных дата-центров создает эти явно противоречивые закономерности. Аналогичным образом, в случае модели А, мы заметили, что точки повышенной температуры отклоняются одним дата центром, который работает при более высокой температуре и обычно имеет более высокую частоту ошибок даже при низких температурах.
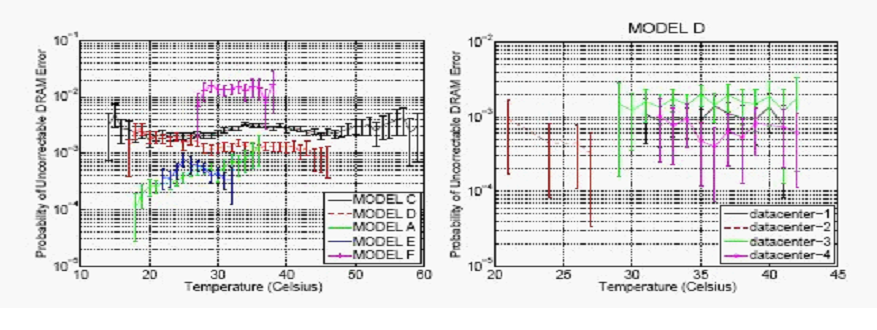
Рисунок 9: Вероятность фатальных ошибок DRAM в ЦОД Google при изменении температуры.
Вывод 8: Мы не нашли подтверждения повышения частоты фатальных ошибок DRAM, замены DRAM DIMM или отказов узлов, вызываемых проблемами DRAM при изменении температуры в пределах данных по диапазонам температур.
2.4 Температура и отказы узлов
2.4.1 Освещение проблемы и исходные данные
В этом разделе рассматривается влияние температуры не на отдельные аппаратные компонента, а на надежность и доступность системы в целом. В своем исследовании мы использовали данные из двух разных источников. Первый источник включает предоставленные LANL наборы данных LANL-Type-1 и LANL-Type-2. Мы не ограничивались в своем анализе данными по отказам узлов, связанных с DRAM, и включили в него все отказы узлов, связанные с аппаратными проблемами. Второй источник включает предоставленные SciNet-GPC данные по замене оборудования, но и здесь мы использовали данные по замене всех любых аппаратных компонентов, а не только модулей DRAM.
2.4.2 Анализ
На рисунке 11 показано воздействие температуры на частоту отказов узлов в LANL. На рисунке 11 (слева) показана среднемесячная вероятность отказов узлов в зависимости от изменения средней (рабочей) температуры узла для системы 20 в наборе данных LANL, так как по этой системы были доступны результаты измерений температуры.
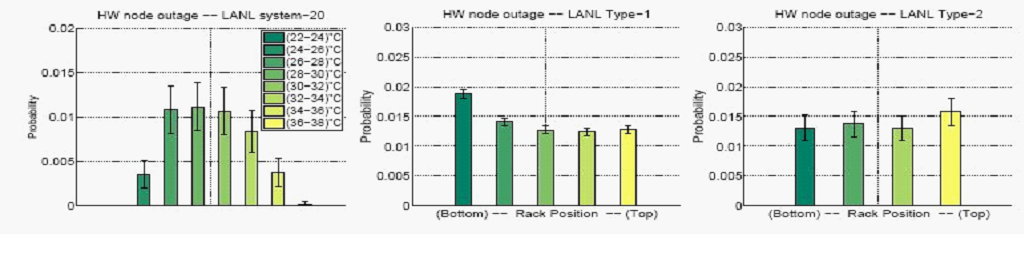
Рисунок 11: Вероятность отказа узлов LANL при изменении температуры (слева) и положения стойки в качестве индикатора температуры (посередине, справа).
На рисунке 11 (в центре, справа) показана среднемесячная вероятность отказа узлов в зависимости от положения узла в стойке (нижнее или верхнее положение, т.e. более низкая или более высокая температура) для систем LANL-Type-1 и LANL-Type-2. В пределах диапазона температур, охватываемого нашими данными, мы не нашли никакого подтверждения того, что узлы с более высокой температурой имеют более высокую вероятность выхода из строя, чем узлы с более низкой температурой. Результаты были схожими для замен оборудования, отмеченных в SciNet (Рис. 12): никакого подтверждения того, что замена оборудования чаще проводится в узлах вверху стойки, чем в узлах внизу стойки.
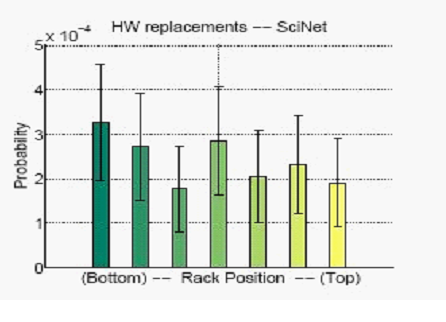
Рисунок 12: Вероятность замены оборудования в SciNet.
Что касается данных LANL, мы также располагаем информацией о продолжительности отказов узлов, т.e., сколько времени потребовалось на возобновление работы узла. На рисунке 10 показаны ящичковые диаграммы общей продолжительности простоя всех узлов в месяц для системы 20. Мы пришли к заключению, что простой узлов с более высокой температурой незначительно отличается от простоя узлов с более низкой температурой, так как оба средних значения, а также верхний и нижний квартили простоя являются схожими.
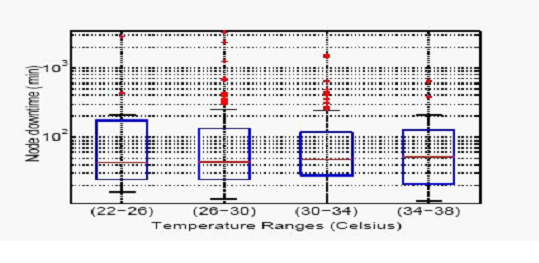
Рисунок 10: Ящичковые диаграммы по простою узлов при изменении температуры.
Вывод 9: Мы не нашли никакого подтверждения того, что узлы с более высокой температурой имеют более высокие уровни отказов узлов, времени простоя и замены оборудования, чем узлы с более низкой температурой.
Можно было бы задать вопрос о том, что в большей степени влияет на отказы узлов: изменчивость температуры или средняя температура. Единственный набор данных, который позволяет нам ответить на этот вопрос, является информация по системе 20, предоставленная LANL. На рисунке 13 (справа) показана среднемесячная вероятность отказа узлов в системе LANL-system-20 в зависимости от коэффициента изменения температуры. На рисунке сравнивается вероятность отказа 50% верхних узлов с самым высоким CoV и 50% нижних узлов с самым низким CoV. Мы обратили внимание на то, что узлы с более высоким CoV имеют значительно большую частоту отказов. Для сравнения, мы также построили график вероятности отказа узлов в зависимости от средней температуры рисунок 13 (слева) и не заметили никакой разницы между узлами с высокой и низкой температурами.
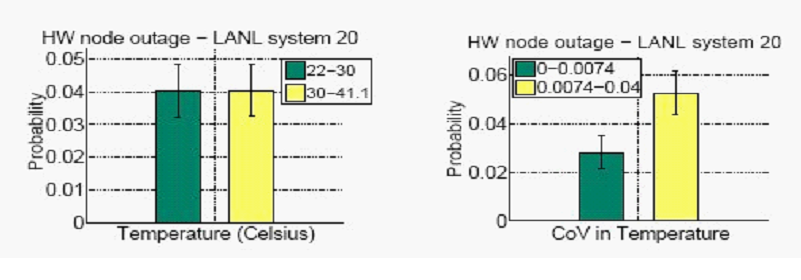
Рисунок 13: Вероятность отказов узлов в зависимости от температуры (слева) и коэффициента изменения (справа).
Вывод 10: Мы пришли к заключению, что высокая изменчивость температуры, по-видимому, имеет более сильное воздействие на надежность узла, чем средняя температура.
Оригинал исследования размещен на сайте http://www.cs.toronto.edu/~nosayba/temperature_cam.pdf.
Ссылки на источники:
[1] Operational Data to Support and Enable Computer Science Research, Los Alamos National Laboratory. http://institute.lanl.gov/data/fdata/.
[2] SciNet. http://www.scinet.utoronto.ca/.
[3] S. F. Altschul, W. Gish, W. Miller, E. W. Myers, and D. J. Lipman. Basic local alignment search tool. Journal of Molecular Biology, 215 (3):403–410, 1990.
[4] D. Anderson, J. Dykes, and E. Riedel. More than an interface—SCSI vs. ATA. In Proc. of FAST 2003.
[5] L. N. Bairavasundaram, G. R. Goodson, S. Pasupathy, and J. Schindler. An Analysis of Latent Sector Errors in Disk Drives. In Proc. of SIGMETRICS'07, 2007.
[6] C. Belady, A. Rawson, J. Peuger, and T. Cader. The Green Grid Data Center Power Eciency Metrics: PUE & DCiE. Technical report, Green Grid, 2008.
[7] D. J. Bradley, R. E. Harper, and S. W. Hunter. Workload-based power management for parallel computer systems. IBM J.Res.Dev., 47:703–718, 2003.
[8] J. Brandon. Going Green In The Data Center: Practical Steps For Your SME To Become More Environmentally Friendly. Processor, 29, Sept. 2007.
[9] California Energy Commission. Summertime energy-saving tips for businesses. consumerenergycenter.org/tips/business summer.html.
[10] G. Cole. Estimating drive reliability in desktop computers and consumer electronics systems. TP-338.1. Seagate. 2000.
[11] H. J. Curnow, B. A. Wichmann, and T. Si. A synthetic benchmark. The Computer Journal, 19:43–49, 1976.
[12] A. E. Darling, L. Carey, and W. -c. Feng. The design, implementation, and evaluation of mpiblast. In In Proc. of ClusterWorld 2003, 2003.
[13] N. El-Sayed, I. Stefanovici, G. Amvrosiadis, A. A. Hwang, and B. Schroeder. Temperature management in data centers: Why some (might) like it hot. Technical Report TECHNICAL REPORT CSRG-615, University of Toronto, 2012.
[14] K. Flautner and T. Mudge. Vertigo: automatic performance-setting for linux. In Proc. of OSDI, 2002.
[15] A. Gandhi, M. Harchol-Balter, R. Das, and C. Lefurgy. Optimal power allocation in server farms. In Proc. of Sigmetrics '09, 2009.
[16] JEDEC Global Standards for the Microelectronics Industry. Arrhenius equation for reliability.
http://www.jedec.org/standards-documents/dictionary/terms/arrhenius-equation-reliability
[17] J. M. Kaplan, W. Forrest, and N. Kindler. Revolutionizing data center energy eciency. Technical report, McKinsey & Company, July 2008.
[18] J. Katcher. Postmark: a new le system benchmark. Network Appliance Tech Report TR3022, Oct. 1997.
[19] Lawrence Berkeley National Labs. Benchmarking Data Centers. benchmarking-dc.html, December 2007.
[20] J. D. McCalpin. Memory bandwidth and machine balance in current high performance computers. IEEE Comp. Soc. TCCA Newsletter, pages 19–25, Dec. 1995.
[21] L. McVoy and C. Staelin. lmbench: portable tools for performance analysis. In Proc. of USENIX ATC, 1996.
[22] D. C. Niemi. Unixbench. http://www.tux.org/pub/tux/niemi/unixbench/.
[23] C. D. Patel, C. E. Bash, R. Sharma, and M. Beitelmal. Smart cooling of data centers. In Proc. of IPACK, 2003.
[24] M. Patterson. The eect of data center temperature on energy eciency. In Proc. of ITHERM, May 2008.
[25] E. Pinheiro, R. Bianchini, E. V. Carrera, and T. Heath. Load balancing and unbalancing for power and performance in cluster-based systems, 2001.
[26] E. Pinheiro, W. D. Weber, and L. A. Barroso. Failure trends in a large disk drive population. In Proc. Of Usenix FAST 2007.
[27] S. J. Plimpton, R. Brightwell, C. Vaughan, K. Underwood, and M. Davis. A Simple Synchronous Distributed-Memory Algorithm for the HPCC RandomAccess Benchmark. In IEEE Cluster Computing, Sept. 2006.
[28] K. Rajamani and C. Lefurgy. On evaluating request-distribution schemes for saving energy in server clusters. In Proc. of the IEEE ISPASS, 2003.
[29] Rich Miller. Google: Raise your data center temperature. http://www.datacenterknowledge.com/archives/2008/10/14/google-raise-your-data-centertemperature/, 2008.
[30] B. Schroeder and G. Gibson. A large-scale study of failures in high-performance computing systems. In Proc. of DSN'06, 2006.
[31] B. Schroeder and G. A. Gibson. Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? In Proc. of USENIX FAST, 2007.
[32] B. Schroeder, E. Pinheiro, and W. -D. Weber. DRAM errors in the wild: a large-scale eld study. In Proc. Of SIGMETRICS '09, 2009.
[33] R. Sharma, C. Bash, C. Patel, R. Friedrich, and J. Chase. Balance of power: dynamic thermal management for internet data centers. IEEE Internet Computing, 9 (1):42–49, 2005.
[34] C. Staelin. Lmbench3: Measuring scalability. Technical report, HP Laboratories Israel, 2002.
[35] R. F. Sullivan. Alternating Cold and Hot Aisles Provides More Reliable Cooling for Server Farms. In Uptime Institute, 2000.
[36] T10 Technical Committee. SCSI Block Commands –3, Rev.25. Work. Draft T10/1799-D, ANSI INCITS.
[37] T13 Technical Committee. ATA 8 — ATA/ATAPI Command Set, Rev.4a. Work. Draft T13/1699-D, ANSI INCITS.
[38] Transaction Processing Performance Council. TPC Benchmark C — Rev. 5.11. Standard, Feb. 2010.
[39] Transaction Processing Performance Council. TPC Benchmark H — Rev. 2.14.2. Standard, June 2011.
[40] R. P. Weicker. Dhrystone: a synthetic systems programming benchmark. Communications of the ACM, 27 (10):1013–1030, Oct. 1984.
 Главная
Главная